A brief history of Computer Vision and AI Image Recognition
Artificial intelligence is already changing how many industries operate.
This was not always the case. As recently as 2014, IBM was reported to be struggling to apply its young super-computer technology to everyday use, and the future for Watson was starting to look bleak, amid skyrocketing costs and insufficient accuracy.
Recent technological progress however, has inverted that course. And while dystopian futures – ranging from AI apocalypse to the end of jobs – or over-optimistic ones (“the singularity is near”) get all the press, huge strides have been made in AI when applied to specific processes, most of them revolving around analyzing the plethora of data each of us is generating through our digital activity, that platforms are gladly vacuuming up.
One such process is image recognition, which has its roots in computer vision. Let’s dive into its history.
The early days of computer vision
When computer vision started to take shape as a field in the 1960s, its aim was to try and mimic human vision systems and ask computers to tell us what they see, automating the process of image analysis. This kind of technology is the precursor to artificially intelligent image recognition. Before, any kind of image analysis had to be done manually, from x-rays to MRIs to hi-res space photography.
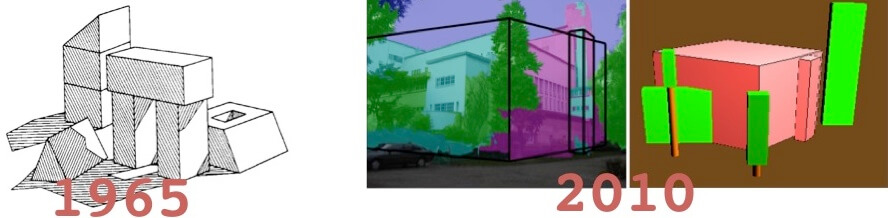
By: Tombone's Computer Vision Blog
Just like animals, computers “see” the world differently from us humans: basically, they count the number of pixels, try to discern borders between objects by measuring shades of color, and estimate spatial relations between objects.
As computer vision evolved, algorithms started to be programmed to solve individual challenges, and they become better at doing the job the more they repeat the task.

Example: CCTV cameras in London Underground stations programmed to spot static / abandoned objects
Fast forward to 2010 (and beyond), we have seen an acceleration in improved deep learning techniques and technology. With deep learning, we’re now able to program supercomputers to train themselves, self-improve over time and provide portions of these capabilities to businesses as online applications, like cloud-based apps.
In order for these machines to learn, they need to be fed data.
In a world where the biggest players like Facebook and Instagram limit how much of their content other actors are able to tap into, there’s been a rise in open-source projects such as ImageNet. ImageNet’s mission is to create a large-scale image database that researchers can tap into in order to train and manufacture their algorithms.
The challenge is that in order for computers to index and catalogue these huge sets of data, they initially need to have some human input in terms tagging and classifying their ‘training images’. Deep learning algorithms then use this information to create benchmarks to compare future images with, but need to be fed large quantities of training images, as many as 10s of millions.
Deep learning and Vertical Image Recognition

DenseNet visualization via Deep Learning for Image Recognition: why it’s challenging, where we’ve been, and what’s next
Thanks to ever-improving deep learning technology, we are seeing an increased rate of images that are being recognized in services which are trained and deployed for specific categories. Rather than utilizing image recognition software to identify images of a generic food dish - such as a salad - that is being shared by users on social media, services that have been trained to identify food can now find for specific ingredients in the salad.
This narrowing of the scope of image recognition to specific sectors has come to be known as 'vertical' AI and a handful of companies, such as Pulsar, are leading the way in integrating it with large swathes of public data.
Through Vertical AI, users can now run images through an algorithm and ensure the results are within the desired context. If an image of food is passed through the ‘color’ module which has been trained to identify colors, the user will receive an analysis of the colors shown in the image, rather than insights about the ingredients.
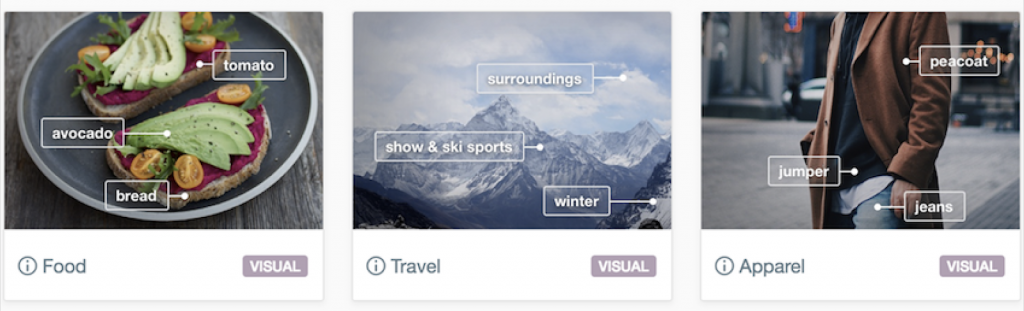
Vertical AI on Pulsar
One example: we ran 15k Instagram posts tagged as #vegan through our food vertical AI, in order to recognize which foods were most photographed by vegan Instagram users.
This methodology adds context to the use of AI for business applications. Just like in one of the image examples above showing a station security camera identifying an abandoned object, vertical image recognition will be deployed to solve specific challenges, rather than offering the one-size-fits-all model which some have lead us to expect.
Where are we heading?
In the coming years, we will notice a steep rise in the use of computer vision and image recognition through deep learning, as well as a growing use of this technology in business applications. One area which has been grabbing headlines is driverless cars, which rely heavily on deep-learning and new image capture techniques to “see” and learn about their surroundings.
As these technologies become more powerful, it’s not just businesses and researchers who are able to tap into them: many are already concerned about the many potential misuses, such as deep fake videos or AI-generated fake-porn. Hopefully, as AI begins to permeate more and more areas of our lives, we will all understand these implications.